If you have read my comments on hackernews, you might have seen that I have been in an somewhat-obsession/experiments to archive "archive.is" pages...
Why do I wish to archive, an service which archives itself, you may ask? I am assuming that you might know about the things which have happened but I recommend reading 0 & 1 if you are unfamiliar.
I am just sad to see an precious tool like archive.is and all the controversy that ensued, sure its debatable as to which side you might take, but I am neutral within this take and I wish to stay this way :-) [And if perhaps archive.is or the journalist is reading, I wish you both to have a nice day in this spirit and I just hope that the controversy can end soon from both sides please.]
I really love archiving. So I wanted to make something within this space, after multiple experiments the previous night, I have been able to make something that I am really proud of and its really elegant.
I call it htmlpipe 2 and this is what this article's nitty gritty is going to be all about which is a static web page currently hosted on my github pages (link 3) but anyone can host it, I wish to tell all readers more about it :-)
Essentially, this project combined with Singlefile4 can be used to archive archive.is pages onto archive.org pages for good measure and it is just an prototype for archival purposes as I really love all the spirit within the archival space.
It's an anonymous way (for the most part) to upload archive.is articles to archive.org, it uses the legendary piping-server 5 by nwgtck project on which I previously had made another project too, so show some love to the piping-server and this is why I have also named this project HTMLPipe in homage to it
Now, I wish to write this blog-post as also an tutorial on how to use my project/(Also please fork/star my own github project to create your own github pages instance of it too) I will also write a more technical background as to how this works within this but after I write the tutorial on how to use this :)
I am going to be taking this https://archive.is/g3Bok link which points to https://www.newyorker.com/culture/annals-of-inquiry/when-do-we-become-adults-really for the purposes of showing you how to use my project.
Firstly, go to the archive.is page and fill up the captcha if it comes and then go to the main archive.is article
and then use singlefile extension to create a html page of that archive.is article
In this case, it was a 2.4 MB article combined into a single html
Now go to ppng.io and simply upload the html 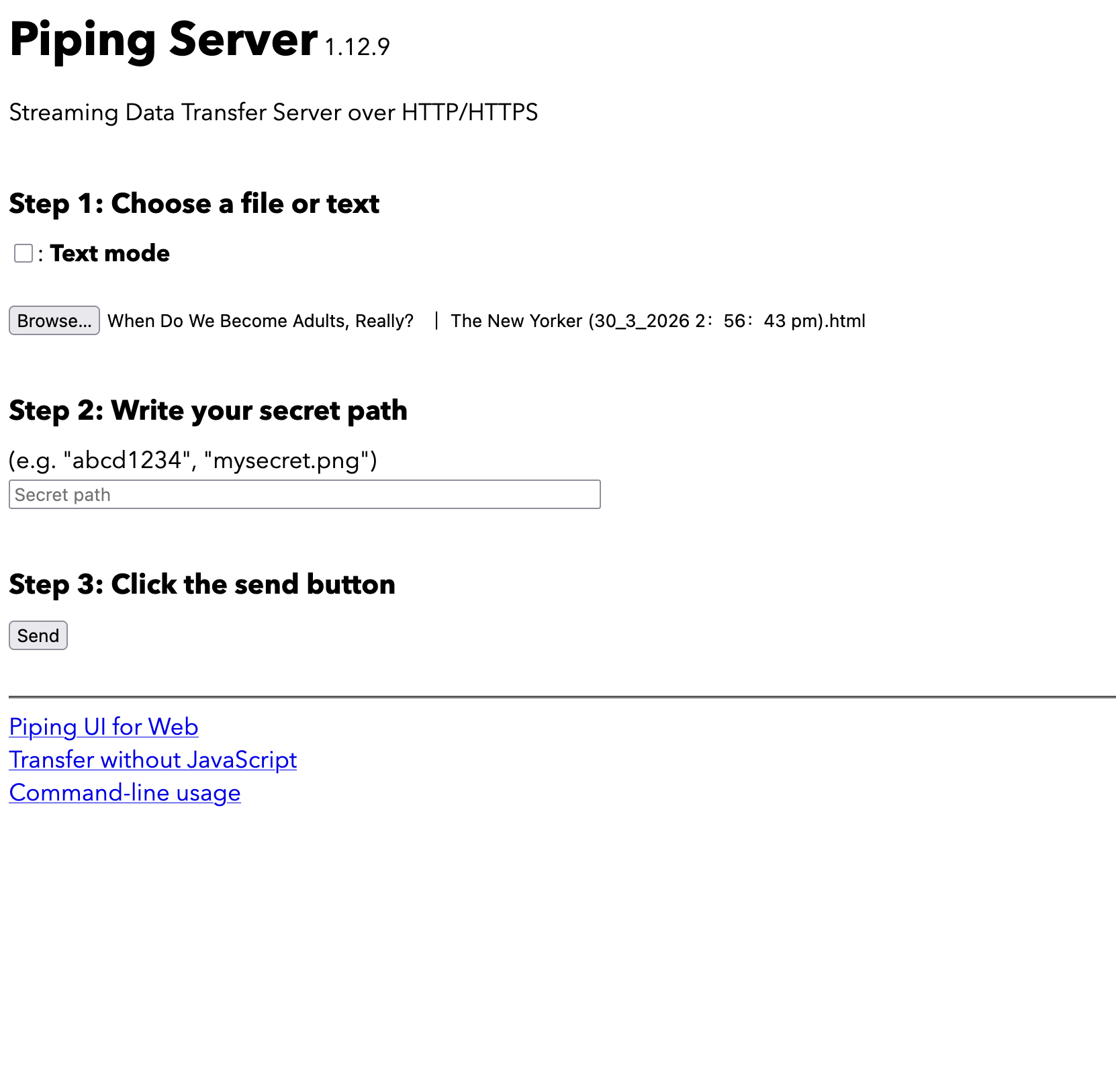
Now take a random htmlpath, now in this case I am taking it to be as nt3nn which I got from taking a random string from random.org
I suggest having a random string which hasn't been used before otherwise there can be some more nuance to it
and then, click on send.
This will wait at I think 2.65% or just a few KB's and that's great.
Now, go to https://serjaimelannister.github.io/htmlpipe/?https://ppng.io/the random-text-you-entered
so in this case it would be https://serjaimelannister.github.io/htmlpipe/?https://ppng.io/nt3nn
now simply copy this and paste it into web.archive.org save page input and click on save
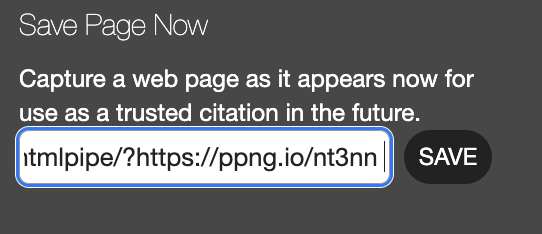
Now this page has been archived: https://web.archive.org/web/20260330093536/https://serjaimelannister.github.io/htmlpipe/?https://ppng.io/nt3nn
when you go through this, you might see that you have to wait for a few seconds, that has to do with the more technical implementation of it but you will see that after just a few seconds, this ends up working
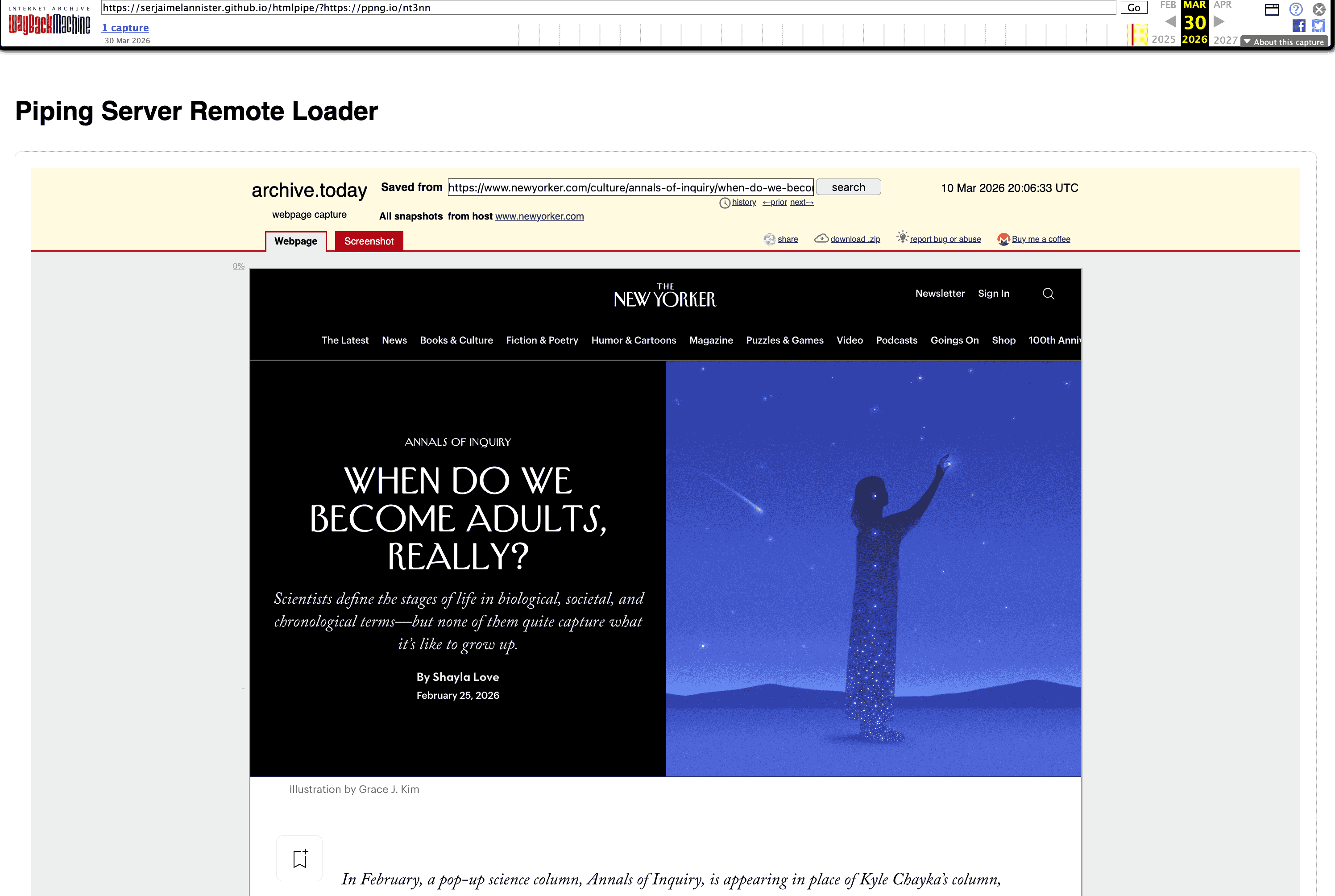
That is it :)
Now what is the technical aspects to it:
Essentially piping server allows to stream text/files from terminal/browser to a particular ppng.io link
the ppng.io link has html file but it shows itself within plaint text format so html isn't formatted
what the static page does is contacts the ppng.io page and gets the raw html and then displays it
This all happens also when you archive a page and it also archives the piping server link as well
Piping server is also open source and has many people hosting it and you can host it too and essentially host everything about it but also host individual parts, for example someone can host a piping server and the other can host a github pages htmlpipe themselves too :)
I am really proud of what I have made and thus feel like sharing it I wish that something like this can be used for archive pages too from now on
I will be trying to convert comments linking to archive using this method and linking to this blog post for them to better understand this as I genuinely feel like I have made something meaningful within the archival space and I am proud of it in my own way :-)
Have a nice day to everyone who is reading it, please feel free to star the piping server project by nwgtck and donating to all archive projects and respect towards all people who work within the archival space.